데이터베이스의 가장 기본적인 작업은 데이터를 받으면 저장하고, 데이터를 요청하면 제공하는 역할을 한다
대개 일반적인 개발자는 저장소 엔진을 구현하기보다 사용 가능한 여러 저장소 중 적합한 저장소를 선택한다.
따라서 데이터베이스가 저장/검색을 내부적으로 처리하는 방법을 알아야 상황마다 적합한 저장소를 선택할수 있다.
아주 간단한 데이터베이스를 만들어보자
db_set () {
echo "$1,$2" >> database
}
db_get () {
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}위의 기본 데이터베이스는, db_set 할때마다 key-value 형태로 파일에 끝에 추가한다.
키를 여려번 갱신해도 이전 버전을 덮어쓰지 않으므로, 최신 값을 찾기 위해서 키의 마지막 항목을 봐야 한다.
매우 간단한 작업의 경우 위의 db_set 같이 파일에 끝에 추가하는 구조는 꽤 좋은 성능을 보여준다.
많은 데이터베이스는 위의 db_set 같은 추가전용 데이터 파일인 로그를 사용한다.
반면, db_get 같은 경우 레코드가 많을수록 성능이 좋지 않다.
특정 키의 값을 효율적으로 찾기 위해서는 다른 데이터 구조가 필요하다.
이를 위해 색인이란 개념을 사용한다.
색인
색인은 원하는 데이터를 찾는데 도움을 주는 부가적인 메타데이터를 유지한다.
기본데이터에서 파생되는 추가적인 구조이고, 색인도 추가와 삭제가 가능하다.
어떤 종류의 색인이라도 데이터를 쓸때마다 색인을 갱신해야 하므로 쓰기 속도를 느리게 만든다.
이는 저장소에서 중요한 트레이드오프이다. 따라서 모든 데이터를 색인하기 보다 필요한 데이터만 색인 해야한다.
해시 색인
인메모리 데이터 구조를 위한 해시맵을 사용하여 색인을 만들어 보자
데이터를 단순히 파일에 추가하는 방식으로 저장소를 구성한다면, 가장 간단한 색인 전략은 키를 데이터 파일의 오프셋에 맵핑하는 것이다.

위 그림을 보면, 각 키별로 디스크상의 바이트 오프셋에 맵핑한 정보를 인메모리 해시맵 형태로 유지하고 있다.
키에 해당하는 데이터가 변경이 된다면, 기존 값을 수정하는게 아닌 값이 새롭게 추가되고, 해시맵의 바이트 오프셋만 변경한다.
위와 같은 방법으로 파일에 항상 추가만 한다면 결국 디스크 공간이 부족해 질것이다.
이는 어떻게 해결할수 있을까?
로그를 특정 크기의 세그먼트로 나누고 컴팩션 작업을 하는 방식이 좋은 해결책이 될 수 있다.

컴팩션을 수행할 때 여러 세그먼트를 병합 할 수 있다.
세그먼트 병합과 컴팩션은 백그라운드 스레드로 수행 가능하기 때문에 읽기/쓰기 처리는 정상적으로 계속 수행할 수 있다.
각 세그먼트는 키를 파일 오프셋에 맵핑한 인메모리 해시 테이블을 갖는다.
키의 값을 찾으려면 최신 세그먼트를 먼저 확인하여 이전 세그먼트들까지 확인한다.
병합 과정을 통해서 세그먼트 수를 적게 유지하기 때문에 많은 해시 맵을 확인할 필요가 없다.
실제 구현에서 중요한 문제 몇가지를 확인해보자
- 파일 형식 : csv 는 로그에 적합하지 않다. 바이너리 형식이 더 빠르고 간단하다.
- 레코드 삭제 : 키와 관련된 값을 삭제할때 바로 삭제하는 것이 아닌 특수한 삭제 레코드 (ex. 툼스톤)를 추가한다. 실제 삭제는 병합과정에서 삭제된 이전 값을 무시하고 병합하게 된다
- 고장 복구 : 데이터베이스 재시작시 인메모리 해시맵은 손실된다. 전체 세그먼트를 읽으면 복원 가능하지만 시간이 오래걸린다. 일부 데이터베이스는 인메모리 해시맵을 스냅샷 형태로 디스크에 저장해놓는다.
- 동시성 제어 : 쓰기 작업에 대해 엄격한 동시성 제어를 하려면 단일 스레드를 사용한다.
위와같은 추가전용로그와 해시테이블을 이용하는 방법은 아래와 같은 장단점이 있다.
장점
- 로그 추가와 세그먼트 병합은 순차적 쓰기 작업이기 때문에 보통 무작위 쓰기보다 빠르다
- 세그먼트 파일이 추가 전용이나 불변이면 동시성과 고장 복구가 간단하다
- 오래된 세그먼트 병합은 데이터 파일 조각화 문제를 피할 수 있다.
단점
- 해시테이블을 메모리에 저장해야 하므로 키가 너무 많으면 문제가 된다.
- 범위 질의에 효율적이지 않다.
SS(Sorted String) 테이블, LSM (Log-Structured Merge) 트리
위의 단점을 해결하기 위한 SS 테이블 구조를 살펴보자
SS테이블은 세그먼트에 키-값 쌍을 키로 정렬해 저장한다.
각 키는 병합된 세그먼트 파일 내 한번만 나타나야 한다 (컴팩션 과정이 이를 보장한다)
SS테이블은 해시색인 + 로그 세그먼트에 비해 몇가지 장점이 있다.

세그먼트 병합시 파일이 사용 가능한 메모리보다 크더라도 간단하고 효율적이다. 병합정렬 알고리즘과 유사하다.
입력 파일을 함께 읽어 각 파일의 첫번째 키를 보고 가장 낮은 키를 출력 파일로 복사하는 과정을 반복한다.
입력 파일들을 전체를 한번에 읽는게 아닌 첫번째 키를 보고 병합이 가능하다.
만약 여러 입력 세그먼트에 동일한 키가 있다면, 가장 최근 세그먼트의 값을 유지하고 오래된 값을 버린다.
파일에서 특정 키를 찾기 위해 메모리에 모든 키의 색인을 유지할 필요는 없다.
일부 키에 대해서만 인메모리 색인을 유지하더라도, 정렬된 상태로 저장되기 때문에 다른 키들 사이에 있다고 유추할 수 있다.

데이터를 SS 테이블 형태로 삽입 및 유지할수 있을까?
AVL트리, 레드블랙 트리 등을 이용해 임의 순서로 키를 삽입하고 정렬된 순서로 키를 읽어 파일로 쓸수 있다.
아래와 같은 과정을 거쳐 데이터를 유지한다
- 쓰기 요청시 인메모리 균형트리 데이터구조에 추가한다. 이를 멤테이블 이라 한다
- 멤테이블이 임곗값보다 커지면 SS테이블 파일로 디스크에 기록한다. 트리가 이미 정렬된 키-값 쌍을 유지하고 있으므로 효율적으로 수행할 수 있다. 새로운 SS테이블 파일은 최신 세그먼트가 된다
- 읽기 요청은 먼저 멤테이블에서 키를 찾고, 디스크 상 최신 세그먼트부터 이전 세그먼트로 찾는다
- 세그먼트 파일을 합치고 삭제된 값을 버리는 컴팩션을 백그라운드에서 수행한다.
멤테이블에 있는 데이터가 디스크에 쓰기 전에 뎉이터베이스가 고장나면 데이터는 유실된다.
이를 피하기 위해선 분리된 로그를 디스크상에 유지해야 한다. 이 로그는 멤테이블 복원시에만 필요하므로 순서가 정렬되지 않아도 된다.
위와 같이 색인 구조를 로그 구조화 병합 트리 (LSM 트리)라 한다.
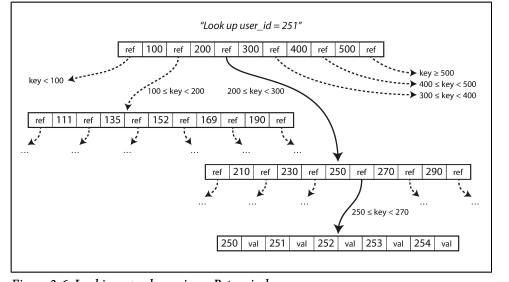
B 트리
B트리는 가장 일반적인 색인 유형이다. 이전까지 설명했던 로그 구조화 색인과는 많이 다르다.
대부분 관계형 데이터베이스에서 표준 색인 구현으로 사용하고, 많은 비관계형 데이터베이스도 사용한다.
B트리는 4KB (때로 더 큰) 고정 크기 블록 이나 페이지로 나누어 한번에 하나의 페이지에 읽기/쓰기를 한다.
페이지는 여러 키와 하위 페이지의 참조를 포함한다.
한 페이지에서 하위 페이지를 참조하는 수를 분기 계수 (branching factor) 라 한다. 이는 보통 수백개에 달한다.
대부분 데이터베이스는 깊이가 3이나 4면 충분하다.
분기계수 500의 4KB 페이지의 4단계 트리는 256TB 까지 저장 가능하다 (500 ^ 4 * 4096B)
한 페이지는 루트로 지정된다.
색인에서 키를 찾으려면 루트에서 시작해 하위 페이지, 리프 페이지까지 참조하며 찾는다.
B트리에서 쓰기는 기본적으로 새로운 데이터를 디스크 상의 페이지에 덮어 쓴다.
페이지를 덮어쓰더라도 페이지를 가리키는 모든 참조는 변하지 않는다. 이는 로그 구조화 색인과 대조적인 점이다.
B 트리와 LSM 트리의 비교
일반적으로 LSM 트리는 쓰기에서 빠르고, B트리는 읽기에서 빠르다고 여겨진다.
LSM 은 읽기시 여러 데이터 구조와 SS테이블 확인이 필요하기 때문이다.
LSM 트리는 B트리보다 쓰기 처리량을 높게 유지할 수 있다.
상대적으로 쓰기 증폭이 낮고, 순차적으로 컴팩션된 SS테이블 파일을 쓰기 때문이다.
LSM 트리는 압축률이 더 좋다. 보통 B트리보다 디스크에 더 적은 파일을 생성한다.
페이지 지향적이지 않고 주기적으로 SS 테이블을 다시 기록하기 때문에 저장소 오버헤드가 낮다.
컴팩션 과정이 때로는 진행중인 읽기/쓰기 성능에 영향을 줄수 있다.
LSM 트리가 높은 처리량을 유지할수 있지만 높은 쓰기 처리량과 함께하는 컴팩션은 문제가 발생한다.
디스크의 쓰기 대역폭은 유한하기 때문에, 초기 쓰기와 멤테이블을 디스크로 플러시 하는 스레드가 같은 대역폭을 공유해야 한다.
컴팩션 설정을 주의깊게 하지 않으면 컴팩션이 쓰기 속도를 따라가지 못해 디스크상에 병합되지 않은 세그먼트 수는 디스크 공간이 부족해 질때까지 증가한다.
B트리는 각 키가 한곳에만 정확히 존재하기 때문에 여러 세그먼트에 같은 키가 존재할 수 있는 세그먼트 보다 트랜잭션 관점에서 더 매력적이다.
'책 정리와 리뷰' 카테고리의 다른 글
| [데이터중심 애플리케이션 설계] 4장 정리 (0) | 2023.07.11 |
|---|---|
| [돈의 흐름에 올라타라] 책 리뷰 (1) | 2023.07.06 |
| [심리학이 제갈량에게 말하다] 책 리뷰 (0) | 2023.05.12 |
| [데이터중심 애플리케이션 설계] 정리 (2) | 2023.05.07 |
| [소프트웨어 아키텍처 101] 파트3 (0) | 2023.05.04 |