출처 : https://if.kakao.com/2022/session/25
if(kakao)dev2022
함께 나아가는 더 나은 세상
if.kakao.com
카카오는 키워드 광고 기능을 제공 하고있고, 대량의 광고 데이터를 각종 필터링을 적용한 데이터를 대시보드를 통해서 제공하고 있다.
해당 세션은 대량의 데이터에 대해 필터링 데이터 대시보드를 제공하면서 겪은 경험에 대해 공유 해주고 있다.

사용자는 위와 같은 필터들을 이용 가능
위와 같은 기능을 제공할때 고려해야할 이슈들 존재
이러한 요구사항을 처리할수 있는 데이터 저장소를 선택해야 했고, 키워드 검색 기능이 있어 ES 를 먼저 고려
키워드 검색 기능, 필터링 OR 조건등은 ES에서 당연히 제공 가능하지만,
도메인의 계층 구조를 반영할 수 있는지, 대량의 데이터와 저장기간이 긴 데이터에 대해서 제공, 정렬, 페이징이 가능 할지 고려가 필요
다수의 연관관계가 필요했고, ES에서 연관관계를 구현하는 방법은 다음과 같은 방법들이 있음

Denormalize 방식은 도메인 데이터가 중복되어 변경에 취약하다
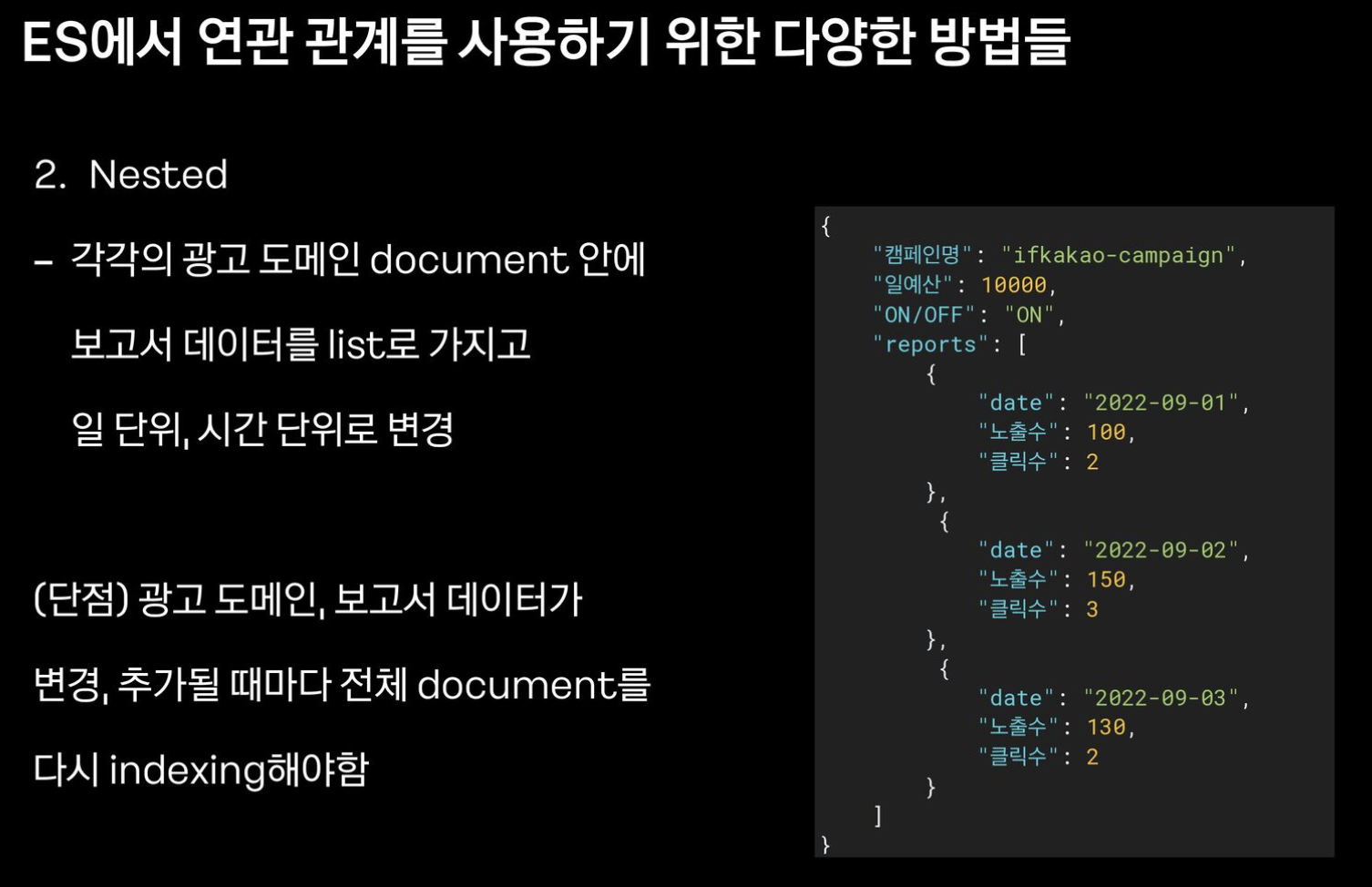
각 도메인 안에 하위 도메인을 nested list 형태로 갖고 있음
상위 도메인, 하위 도메인이 변경/추가될때마다 전체가 인덱싱 되므로 인덱싱시 성능 문제 발생
하위 도메인이 매일/매시간 추가되므로 이 방식은 불가능

인덱스에 연관관계 정보를 담고 있게 함
이 경우 상/하위 도메인이 변경 추가가 자유롭지만 연관관계에 있는 문서는 모두 같은 샤드에 있어야 한다는 단점이 있어야 하고,
많은 연산이 필요하여 쿼리 성능이 나쁠 수 있음
성능 테스트 이전에 실제 저장될 데이터의 사이즈 측정
이후 성능 테스트 진행해보니 ES는 사용이 힘들것 같다는 결론 도달

ES 의 기본 버킷 사이즈는 65536 개여서 해당 데이터는 집계가 불가능한 상황
max_buckets 사이즈를 늘렸더니 데이터 노드가 죽음
그래서 다른 방향으로 선회
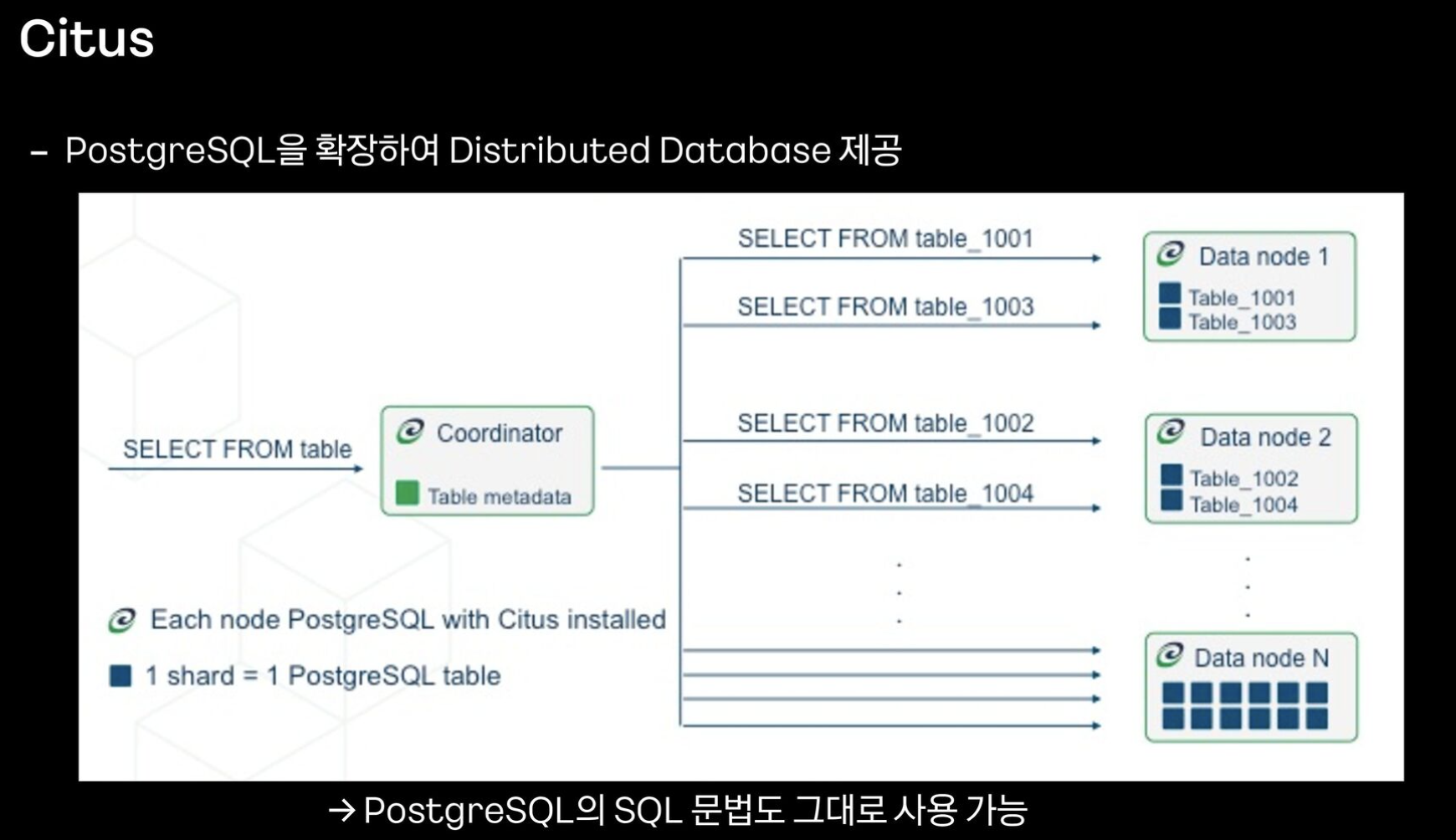
PostgreSQL 을 확장한 Citus (싸이터스) 사용해보기로 결정
이 database 는 postgresql 의 문법을 그대로 사용하면서 distributed database 제공
최초 요구사항중 키워드 검색 검토


응답 결과 수천만개 대상으로 테스트를 했는데 LIKE 검색이 예상보다 성능이 괜찮았음.
Citus 를 쓰기로 결정하고 아키텍쳐 설계 진행

데이터 동기화시 도메인 id 별 개별 트랜잭션 분리 필요
그렇지 않으면 샤드 락이 발생해 deadlock detection 발생
최근 팀내에서 지표관련 데이터를 볼수 있는 툴 개발이 필요한데 이 기능 개발에 좋은 인사이트를 얻을수 있었던것 같다.
팀내에서 ES를 주로 사용하고 있어서 그 안에서 사고가 닫혀 있었던거 같은데 다른 방식으로 생각해볼수도 있을거란 생각이 들었다.
실제 기능개발 이전에 생길수 있는 데이터의 사이즈를 측정하고 테스트를 한게 인상적이었다.
항상 그렇게 해야지 생각은 하지만 쉽게 하기는 쉽지 않은데 대단한것 같다.
PostgreSQL 을 확장한 Citus 를 사용했다는걸 보면서 RDBMS 에서 키워드 검색이 쉽지 않을거란 생각을 했는데 LIKE 쿼리의 성능이 생각보다 괜찮아서 놀랐다. Citus 해당 부분의 구현이 어떻게 되어 있는지 궁금해서 더 찾아봐야 할거 같다.